鉴于之前,数据下载,大家对于历史数据获取比较关心,的确如此,好在有网友先见之明,在数据公布开始,就进行了历史数据的爬取与存储,从而对历史数据的下载成为可能,这里特别感谢知乎用户:李二蛋。
基于其提供的数据接口,从而实现肺炎历史数据的下载。这里将源代码打包成exe工具,可直接使用。
工具下载地址:
链接:https://pan.baidu.com/s/1UN6NES4Y92zbqUMKtPT4ew
提取码:o2c8
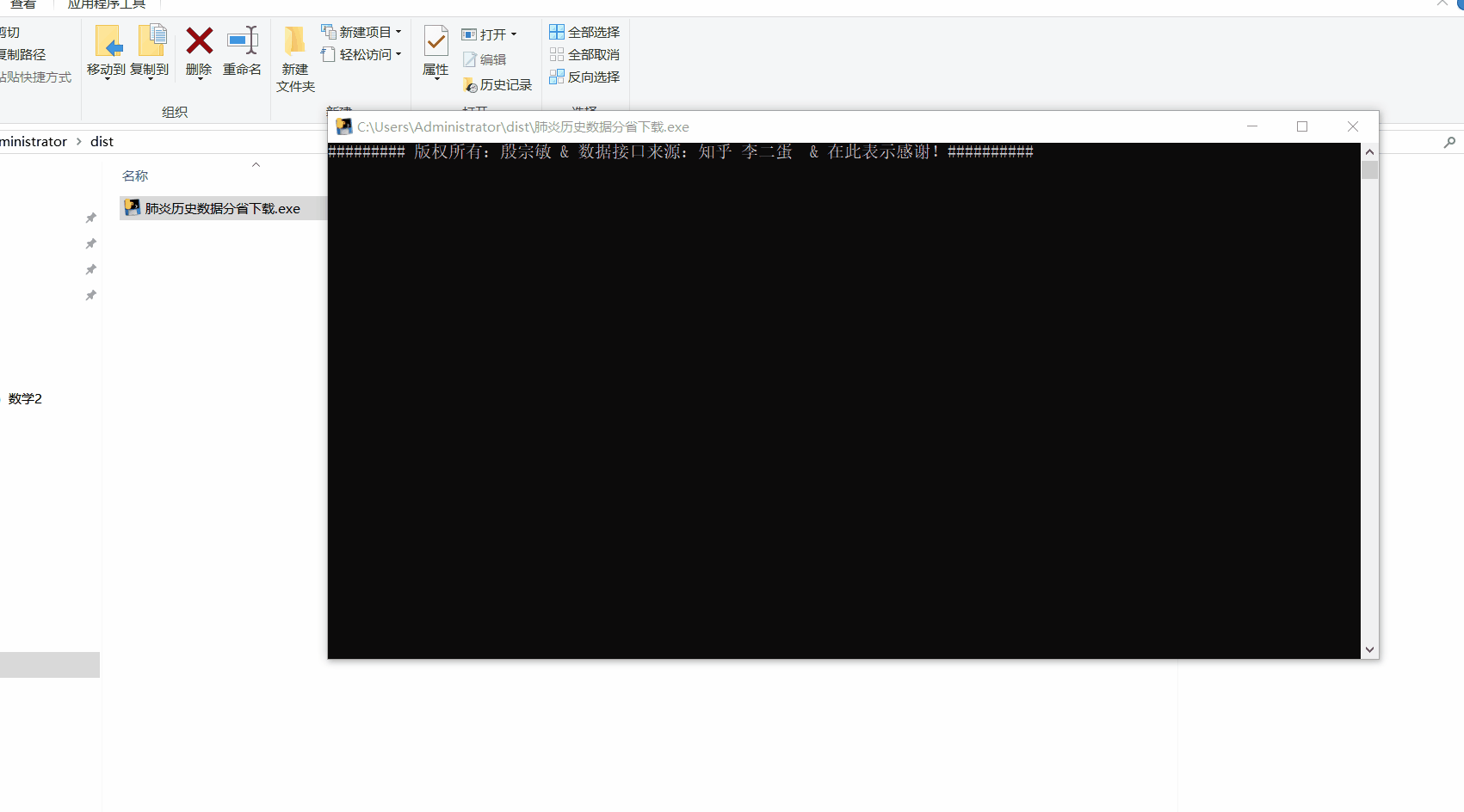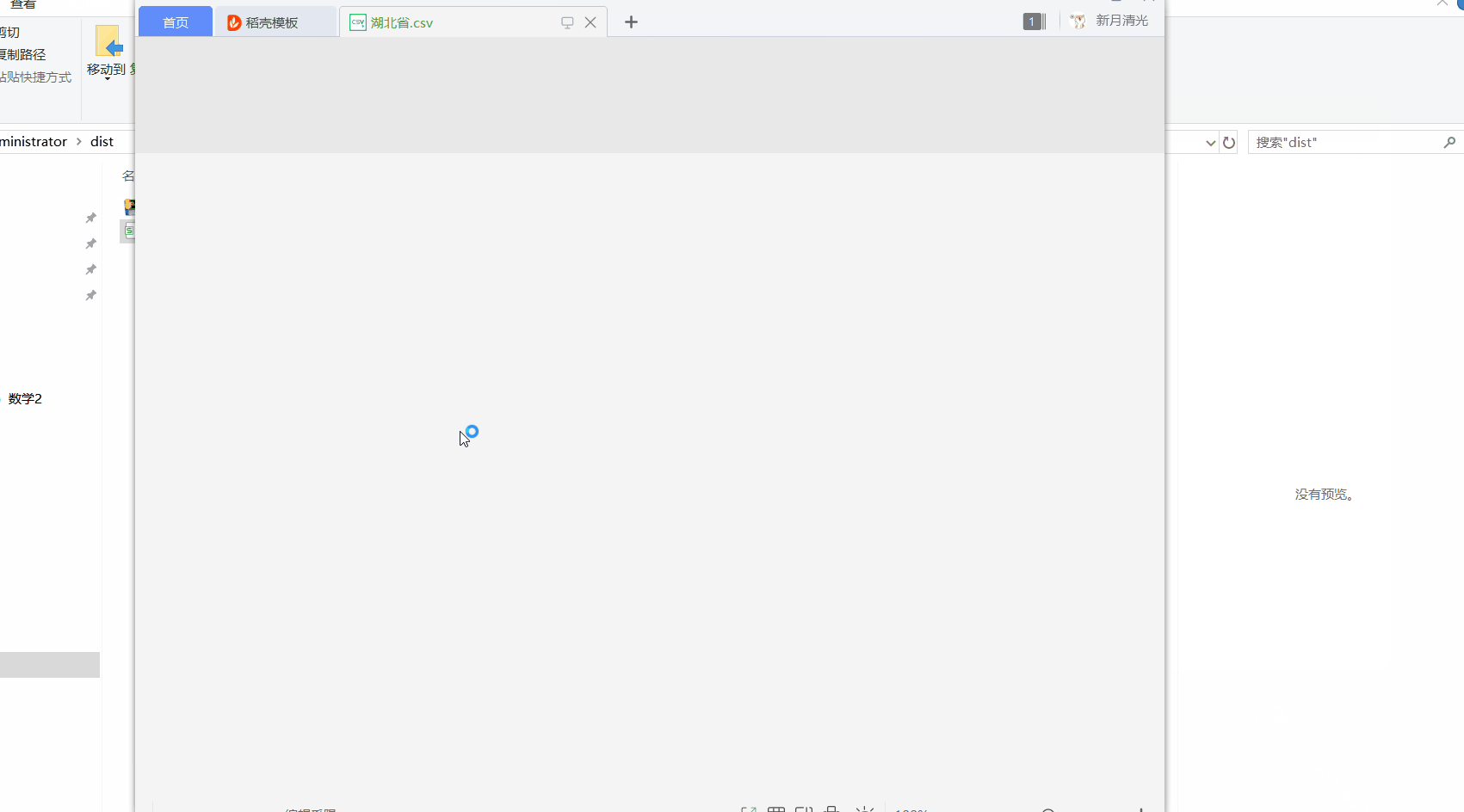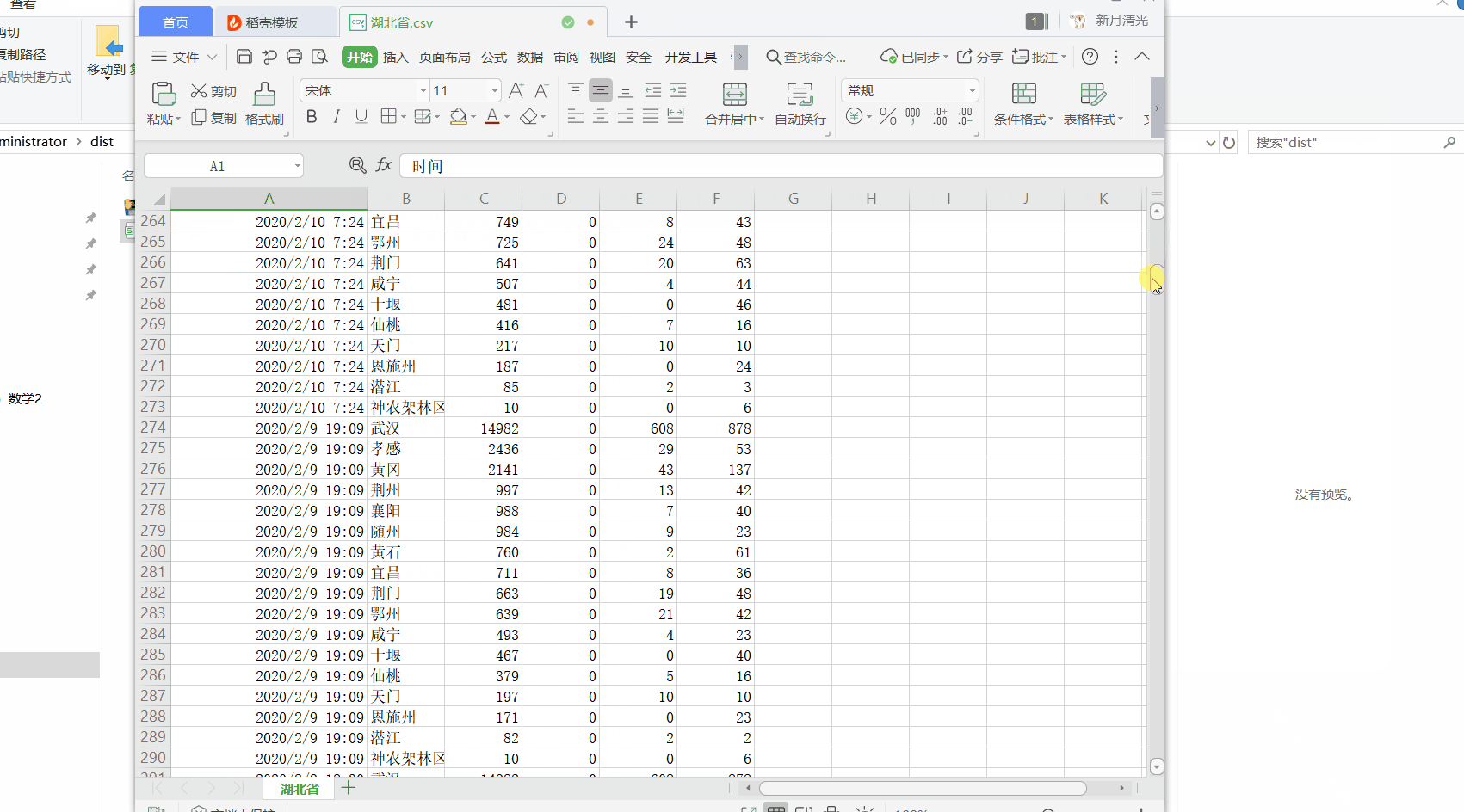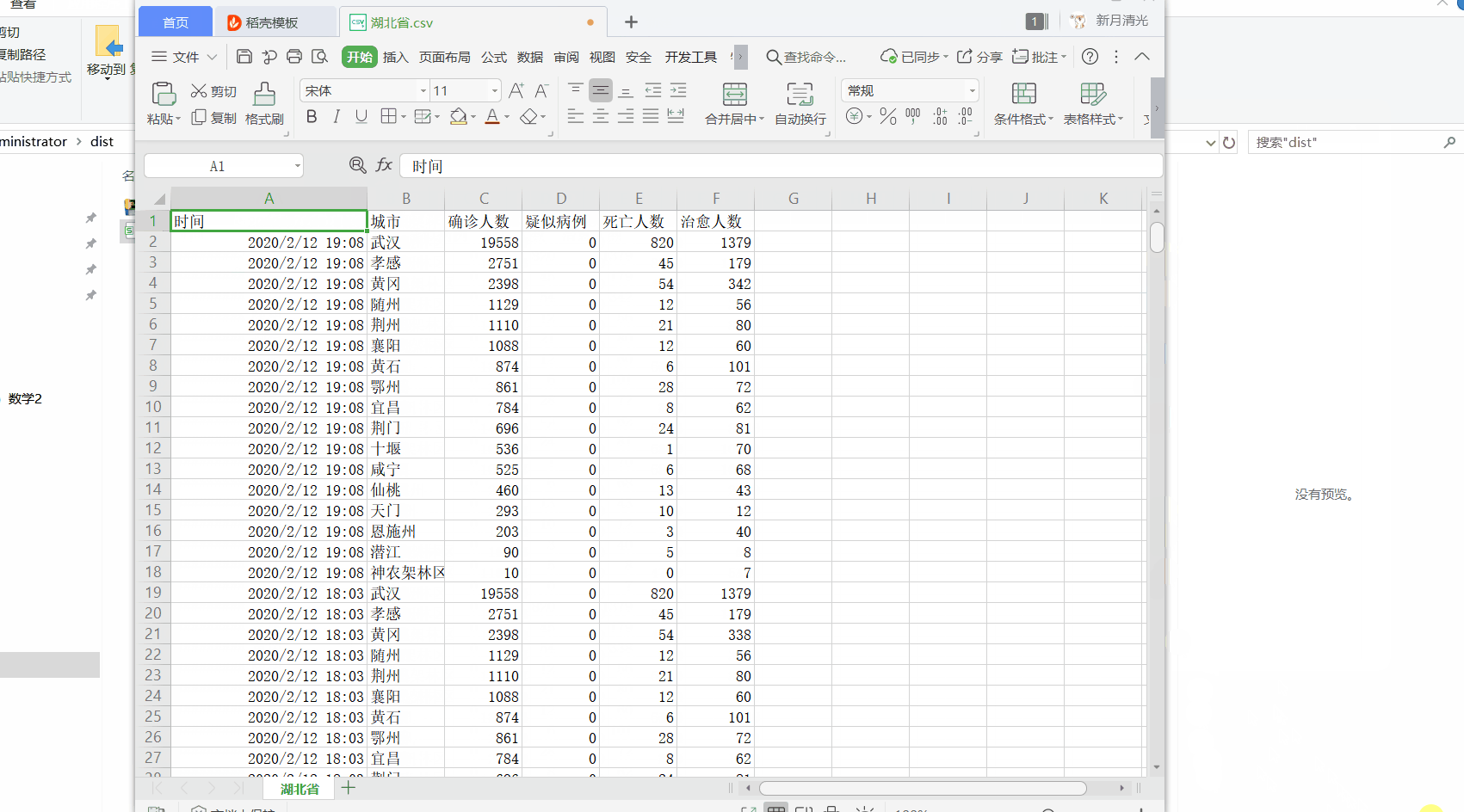
效果如下:
源代码如下:
import requests,re
import json
import time
import csv
print("#########"
" 版权所有:殷宗敏 & 数据接口来源:知乎 李二蛋 & 在此表示感谢!"
"##########")
provinceNames = ['湖北省', '广东省', '河南省', '浙江省', '湖南省', '安徽省', '江西省', '江苏省', '重庆市', '山东省', '四川省', '黑龙江省', '北京市', '上海市', '福建省', '河北省', '陕西省', '广西壮族自治区', '海南省', '云南省', '贵州省', '山西省', '辽宁省', '天津市', '甘肃省', '吉林省', '内蒙古自治区', '新疆维吾尔自治区', '宁夏回族自治区', '青海省', ]
for pro in provinceNames:
url = 'https://lab.isaaclin.cn/nCoV/api/area?latest=0&province='+pro
html = requests.get(url).text
unicodestr=json.loads(html) #将string转化为dict
dat = unicodestr["results"]
header = ['时间', '城市', '确诊人数', '疑似病例', '死亡人数', '治愈人数']
with open('./'+pro+'.csv', encoding='utf-8-sig', mode='w', newline='') as f:
# 编码utf-8后加-sig可解决csv中文写入乱码问题
f_csv = csv.writer(f)
f_csv.writerow(header)
f.close()
def save_data(data):
with open('./'+pro+'.csv', encoding='UTF-8', mode='a+', newline='') as f:
f_csv = csv.writer(f)
f_csv.writerow(data)
f.close()
for i in dat[:-10]:
tim = i.get('updateTime')
timeArray = time.localtime(tim/1000)
formatTime = time.strftime("%Y/%m/%d %H:%M", timeArray)
new_list = i.get('cities')
j = 0
while j < len(new_list):
data = (formatTime)
confirm = (new_list[j]['confirmedCount'])
city = (new_list[j]['cityName'])
suspect = (new_list[j]['suspectedCount'])
dead = (new_list[j]['deadCount'])
heal = (new_list[j]['curedCount'])
tap = (data, city, confirm, suspect, dead, heal)
save_data(tap)
j += 1
print(pro+"的数据下载成功!")
print("#########下载结束!(备注:香港、台湾、澳门、西藏无市区数据)#########")


![本周ASP.NET英文技术文章推荐[02/04 - 02/10]](https://images.cnblogs.com/cnblogs_com/dflying/WindowsLiveWriter/ASP.NET02040210_B32D/vista_ice_house%5B1%5D.jpg)